Get Developer Support
Request Developer Access

LTU Compute API allows to send an image and get all data related to it:
It also allows to compare two images in order to get the distance and the fine differences between them.
No image database is needed. There is no image stored in the platform.
The format files that are currently accepted are: jpg, jpeg, png and gif.

In this documentation are described the available functions of LTU's Compute APIS and how to call them. The API is accessible over the HTTP protocol and is available at this url : https://api.core.ltutech.com/v2/services/image/
The request has been developed in order to make your task easier. It requires a GET or a POST request as input, and returns an HTTP response with the application/json mimetype, which contains the response serialized as a JSON string.
For all the functions in this documentation, the parameters:
application/x-www-form-urlencoded is used to send simple ASCII text data as key=value pairs. key/value pairs are sent as giant query string separated by an &. The lenght of the string and the authorized caracters are limited.
multipart/form-data accept binay or ASCII text data. Parameters are sent separated in the body.
Content-Length: xxxxx #size of the message body
Content-Type: application/x-www-form-urlencoded or multipart/form-data; boundary=--------------------------xxxxxxxxxxxxxxxxxxxxx
Notice that the values of Content-Length and Content-Type could be set automatically by the librairy that you would use.
A token has to be send in the headers of each request to be authorized (except for getToken of course).
The acepted image formats are jpg, jpeg, png and gif.
If everything goes well, all the functions return a JSON result that contains:
{
"result": {
...
},
"details": {
...
},
"vesion": "1.0.0"
}
And in case of error, your will receive an http return error and a message explaning issues in human readable language.
Request AccessTo get access to our services, you will need an account.
To request an account to our development team, please fill in that request form.
Contact UsShould you have any feedback or question please feel free to contact us.
What would you like to do today?
To have access to this service you must be logged. That means you need an account. If you don’t have an account yet, please contact us.
With your login, you could get an token.
 Build a POST request of type application/x-www-form-urlencoded.
Build a POST request of type application/x-www-form-urlencoded.
POST https://iam.dev.ltutech.com/realms/Production/protocol/openid-connect/token
The function takes as input parameters:
headers:
body:
A JSON object containing the bearer access token, its duration of validity in second and the refresh token. Your token is valid for 1 day.
{
"access_token": "eyJhbGciOiJSUzI1NiIsInR5cCIgOiAiSldUIiwi.......wKRTus6PAoHMFlIlYQ75dYiLzzuRMvdXkHl6naLNQ8wYDv4gi7A3eJ163YzXSJf5PmQ",
"expires_in": 600,
"refresh_expires_in": 1800,
"refresh_token": "eyJhbGciOiJIUzI1NiIsInR5cC.......IsInZpZXctcHfX0sInNjb3BlGVtYWlsIHByb2ZpbGUifQ.ePV2aqeDjlg6ih6SA7_x77gT4JYyv7HvK7PLQW-X1mM",
"token_type": "bearer",
"id_token": "eyJhbGciOiJSUz.......JSpqeqpMJYlh4AMJqN6kddtrI4ixZLfwAIj-Qwqn9kzGe-v1-oe80wQXrXzVBG7TJbKm4x5bgCO_B9lnDMrey90rvaKKr48K697ug",
"not-before-policy": 0,
"session_state": "22c8278b-3346-468e-9533-f41f22ed264f",
"scope": "openid email profile"
}
curl -X POST https://iam.dev.ltutech.com/realms/Production/protocol/openid-connect/token -H "Content-Type: application/x-www-form-urlencoded" -d "username=$USERNAME" -d "password=$PASSWORD" -d "grant_type=password" -d "client_id=ltu-api"
import requests
url = "https://iam.dev.ltutech.com/realms/Production/protocol/openid-connect/token"
data={
'username': <your username>,
'password': <your password>,
'client_id': 'ltu-api',
'grant_type': 'password'
}
response = requests.post(url, headers=headers, data=data).json()
token = response["access_token"]
Once expired, you can refresh your token from the refresh token. Also, you don't need to log you again. But be carfull, the refresh token has a duration of validation too.
Build a POST request of application/x-www-form-urlencoded type.
POST https://iam.dev.ltutech.com/realms/Production/protocol/openid-connect/token
This time, the function takes as input parameters:
headers:
body:
A JSON object containing the bearer access token, its duration of validity in second and the refresh token. Your token is valid for 1 day.
{
"access_token": "eyJhbGciOiJSUzI1NiIsInR5cCIgOiAiSldUIiwia2lkIiA6.......wKRTus6PAoHMFlIlYQ75dYiLzzuRMvdXkHl6naLNQ8wYDv4gi7A3eJ163YzXSJf5PmQ",
"expires_in": 600,
"refresh_expires_in": 1800,
"refresh_token": "eyJhbGciOiJIUzI1NiIsInR5cC.......IsInZpZXctcHfX0sInNjb3BlGVtYWlsIHByb2ZpbGUifQ.ePV2aqeDjlg6ih6SA7_x77gT4JYyv7HvK7PLQW-X1mM",
"token_type": "bearer",
"id_token": "eyJhbGciOiJSUz.......JSpqeqpMJYlh4AMJqN6kddtrI4ixZLfwAIj-Qwqn9kzGe-v1-oe80wQXrXzVBG7TJbKm4x5bgCO_B9lnDMrey90rvaKKr48K697ug",
"not-before-policy": 0,
"session_state": "9c5080b1-42e7-4c4b-a00b-60bf947aa206",
"scope": "openid email profile"
}
curl -X POST https://iam.dev.ltutech.com/realms/Production/protocol/openid-connect/token -H "Content-Type: application/x-www-form-urlencoded" -d "refresh_token=$REFRESH_TOKEN" -d 'grant_type=refresh_token' -d "client_id=ltu-api"
import requests
url = "https://iam.dev.ltutech.com/realms/Production/protocol/openid-connect/token"
data={
'refresh_token': {your refresh token},
'client_id': 'ltu-api',
'grant_type': 'refresh_token'
}
response = requests.post(url, headers=headers, data=data).json()
token = response["access_token"]
All the functions found in this documentation work with images. In this section, it is explained how to fill a web request with input images. The different ways of filling it are shown next.
The specifics of how to create a web request depend on the programming language or library you're using. In general, you'll need to specify the HTTP method (usually POST or PUT), the URL of the server endpoint that will receive the request, and any headers or parameters that need to be included in the request. Some headers parameters like the Content-Type or the Content-Length could be automaticaly filled by the library.

Once you have created the web request, you need to attach the image to it. There are a few different ways to do this, depending on the format in which you're sending the image and on which the server accepts. Commons ways that our API accepts are described bellow.
This is probably the most simple way. You can just set the string value of the url as an input parameter generally named image. The Conten-Type could be application/x-www-form-urlencoded or multipart/form-data.
authorization: Bearer <TOKEN>
Accept: */*
Cache-Control: no-cache
Host: api.ltutech.com
Connection: keep-alive
Content-Type: application/x-www-form-urlencoded or multipart/form-data; boundary=--------------------------764488365058661089633609
Content-Length: 63
curl -d 'image=http://data.onprint.com/ltu-core-api/Nobita.jpg' -X POST https://api.core.ltutech.com/v2/services/image/heatMap --header "authorization: Bearer $TOKEN"
import requests
headers = {
'authorization': Bearer <TOKEN>
}
data = {
'image': 'http://image-server.com/my_image.jpeg',
}
url = URL + "image/colorPalette"
result = requests.post(url, headers=headers, data=data)
You can include the image as a part of the resquest's body. In this case, you'll need to use a multipart web request, which allows both binary and text data to be sent to the server for processing. The multipart/form-data encoding will generally be used by the library you are using. The Content-Type is multipart/form-data.
authorization: Bearer <TOKEN>
Accept: */*
Cache-Control: no-cache
Host: api.ltutech.com
Connection: keep-alive
Content-Type: multipart/form-data; boundary=--------------------------764488365058661089633609
Content-Length: 20730
The Content-Type header specifies that the request body is in multipart/form-data format, and the boundary parameter indicates the string that separates each part of the data.
curl -F 'image=@"/user/myimage.jpg"' -X POST https://api.core.ltutech.com/v2/services/image/heatMap --header "authorization: Bearer $TOKEN"
headers = {
'authorization': Bearer <TOKEN>
}
with open(path_img, 'rb') as media:
img = media.read()
data = {
'image': img
}
url = URL + "image/colorPalette"
result = requests.post(url, headers=headers, files=data).json()
In this example, data is a dictionary where the key image corresponds to the parameter name expected by the server to accept the uploaded file.
In this case, you need to open the file as binary and encode it using the binary-to-text base64 schemes (described in RFC 4648) that can be sent over the network and are available in most computing languages. Then just add the parameter generally named image followed by the generated chain of characters. The Content-Type could be multipart/form-data or application/x-www-form-urlencoded.
If the first bytes of your image file look like this:
\xff\xd8\xff\xe0\x00\x10JFIF\x00\x01\x01\x00\x00\x01\x00\x01\x00\x00
The binary encoding should start by:
/9j/4AAQSkZJRgABAQAAAQABAA...
And the beginning of request will look like this after HTML ASCII conversion (generally done by library function or tools):
image=%2F9j%2F4AAQSkZJRgABAQAAAQABAA...
file = open('/path/to/image/file', 'rb')
content = file.read()
# base64 makes the request lighter
# we need to decode("utf8") to add the result as a string to the request
encoded_img=base64.b64encode(content).decode("utf8")
data = {
'image' : encoded_img
}
url = URL + "image/colorPalette"
result = requests.post(url, headers=headers, data=data)
To improve the speed, the images can be compressed using opencv.
import cv2
# Read image from file
# opencv_img is a numpy array where each element is a pixel
opencv_img = cv2.imread(path + "/image.jpg", cv2.IMREAD_UNCHANGED)
# compress the image using opencv's imencode
# encoded_img is a memory buffer (bytes)
encoded_img = cv2.imencode(".png", opencv_img)[1] # extra compression
# encode to base64
# encoded_img is the resulting encoded bytes by base64
encoded_img = base64.b64encode(encoded_img)
data = {
'image' : encoded_img
}
url = "https://api.core.ltutech.com/v2/services/image/colorPalette"
result = requests.post(url, headers=headers, data=data)
Call this API point to compute and obtain the heatmap of an image. Heatmap could be used to understand where are the interesting points for the image searches.

Build a POST request of type multipart/form-data(binary or text) or application/x-www-form-urlencoded(only text) to send the image and its properties.
POST https://api.core.ltutech.com/v2/services/image/heatMap
The function heatMap takes as input:
headers
body:
A JSON object containing in the Heatmap key:
{
"result": {
"heatmap": {
"encoding": "base64",
"format": "image/png",
"value": "/9j/4AAQSkZJRgABAQAAAQABAAD/[...]LgKKKBhRRRQAUUUUAf/Z”
},
"details": {
"name": "heatmap",
"info": {
"signature": 72004000
},
"score": 0,
"message": ""
},
"version": "0.1.0"
}
curl -d 'image=http://data.onprint.com/ltu-core-api/Nobita.jpg' -X POST https://api.core.ltutech.com/v2/services/image/heatMap --header "authorization: Bearer $TOKEN"
import requests
url = "https://api.core.ltutech.com/v2/services/image/heatMap"
headers = {
'authorization': Bearer {token}
}
data = {
'image': 'http://data.onprint.com/ltu-core-api/Nobita.jpg',
}
result = requests.post(url, headers=headers, data=data).json()
The data and headers objects are dictionaries that contains the expected name and the value of the parameters.
Call this API point to get the most prevalent colors within an image.
Build a POST request of type multipart/form-data(binary or text) or application/x-www-form-urlencoded(only text) to send the image and its properties.
POST https://api.core.ltutech.com/v2/services/image/colorPalette
The function colorPalette takes as input:
A JSON object containing a list of colors and their pourcentage: [R, G, G, %]
{
"result": {
"colors": [[164, 21, 54, 64], [140, 7, 32, 20], ... [180, 50, 91, 1]]
},
"details": {
"name": "colorPalette",
"score": 0,
"message": "Found 8 colors",
"info": {
"count": 8,
"format": "RGB%"
}
},
"version": "0.1.0"
}
curl -d 'image=http://data.onprint.com/ltu-core-api/Nobita.jpg' -X POST https://api.core.ltutech.com/v2/services/image/colorPalette --header "authorization: Bearer $TOKEN"
import requests
url = "https://api.core.ltutech.com/v2/services/image/colorPalette"
headers = {
'authorization': Bearer {token}
}
with open(path_img, 'rb') as media:
img = media.read()
files = {
'image': img,
}
# use file to send a binary
result = requests.post(url, headers=headers, files=files).json()
The _files _ and headers objects are dictionaries that contains the expected name and the value of the parameters.
Call this API point to get the binary mask of the single biggest object in an image. This function is mainly useful combined with differences detection for maintenance and quality usecases in order to know what to take in account in the comparison. 1 means object, 0 means background. The mask could be calculted from different algorythms described bellow.

POST https://api.core.ltutech.com/v2/services/image/objectMaskDetection
The function objectMaskDetection takes as input:
Each algorithm uses one or more mathematical process to detach background and foreground, then thresholds the resulting image and finds contours in the binary image generated.
A JSON object containing in the binary mask of an object detailled in the binary mask key:
{
"result": {
"binary mask": {
"encoding": "base64",
"format": "image/png",",
"value": "iVBORw0KGgoAAAANSUhEUgAAA ... VORK5CYII="
}
},
"details": {
"name": "objectMaskDetection",
"score": 0,
"message": "Succeded to detect object using channel V",
"info": {
"channel": "V"
}
},
"version": "0.1.0"
}
curl -F 'image=@"./Nobita.jpg"' -X POST https://api.core.ltutech.com/v2/services/image/objectMaskDetection --header "authorization: Bearer $TOKEN" -F 'algorithm="SOBEL"' -F 'only_biggest="True"'
import requests
url = "https://api.core.ltutech.com/v2/services/image/objectMaskDetection"
headers = {
'authorization': Bearer {token}
}
with open(path_img, 'rb') as media:
img = media.read()
files = {
'image' = img
}
data = {
'image': img,
'channel': 'S'
}
result = requests.post(url, headers=headers, files=files, data=data).json()
The data, the files and the headers objects are dictionaries that contains the expected name and the value of the parameters.
Call this API point to get the contours of single biggest object in an image. This function is mainly useful for combined with differences detection for maintenance and quality usecases in order to help the user to fit an object to analyze to its reference. The contours is calculated from channel S or V in the HSV colors space. S for Saturation, V for value.

Build a POST request of type multipart/form-data(binary or text) or application/x-www-form-urlencoded(only text) to send the image and its properties.
POST https://api.core.ltutech.com/v2/services/image/contours
The function contours takes as input:
a JSON object containing the contours vertices of the object.
{
"result": {
"contours": [
{
"boundingBox": {
x: 224,
y: 65,
width: 343,
height: 660
},
"relativeVertices": [
{
x: 10,
y: 1
},
...
{
x: 11,
y: 0
}
]
}
]
},
"details": {
"name": "contours",
"score": 0,
"message": "Got 9 contours",
"info": {
"nbContours": 9
}
},
"version": "0.1.0"
}
curl -F 'image=@“/Users/Pictures/image.jpg”’ -X POST https://api.core.ltutech.com/v2/services/image/contours --header "authorization: Bearer $TOKEN" -F 'channel:V'
import requests
url = "https://api.core.ltutech.com/v2/services/image/contours"
headers = {
'authorization': Bearer {token}
}
with open(path_img, 'rb') as media:
img = media.read()
files = {
'image': img
}
data = {
'channel': 'V'
}
result = requests.post(url, headers=headers, files=file, data=data).json()
The file, the data and the headers objects are dictionaries that contains the expected name and the value of the parameters.
Call this API point to get edges presents in an image. This function is mainly useful combined with differences detection for maintenance and quality usecases. This helps the user to fit the object to analyze to its reference. The edges are defined as the intensity variation between pixels.

Build a POST request of type multipart/form-data(binary or text) or application/x-www-form-urlencoded(only text) to send the image and its properties.
POST https://api.core.ltutech.com/v2/services/image/edges
The function edges takes as input:
a JSON object containing edges drawn in a binary image.
▼{
"result": {
"edges": {
"encoding": "base64",
"format": "image/png",
"value": "iVBORw0KG...goAAAANSUhE"
}
},
"details": {
"name": "edges",
"score": 0,
"message": "Edges found.",
"info": {}
},
"version": "1.1.3.12"
}
curl -F 'image=@“/Users/Pictures/image.jpg”’ -X POST https://api.core.ltutech.com/v2/services/image/edges --header "authorization: Bearer $TOKEN" -F 'threshold_min=50' -F 'threshold_max=100' -F 'edge_thickness=1'
import requests
url = "https://api.core.ltutech.com/v2/services/image/edges"
headers = {
'authorization': Bearer {token}
}
with open(path_img, 'rb') as media:
img = media.read()
files = {
'image': img
}
data = {
'threshold_min'=50,
'threshold_max'=10
'edge_thicknesse=1
}
result = requests.post(url, headers=headers, files=file, data=data).json()
The file, the data and the headers objects are dictionaries that contains the expected name and the value of the parameters.
The LTU Compute API allows to access external functions library to get more information from your images, such as text, objects detection or labellisation. The LTU Core API currently calls Google images algorithms as external library.
Call this API point to know how blured, overexposed, underexposed is your image. This function is useful for maintenance and quality usecases to guarantee the quality of an image before processing it.

Build a POST request of type multipart/form-data(binary or text) or application/x-www-form-urlencoded(only text) to send the image and its properties.
POST https://api.core.ltutech.com/v2/services/image/imageQuality
The function imageQuality takes as input:
A JSON object containing:
{
"result": {
"encoding": "OK",
"brightness": {
"under_per": 56.778936910084454,
"under_mask": {
"encoding": "base64",
"format": "image/png",
"value": "iVBORw0K...GgoAAAANSUhE"
}
"over_per": 0.7113760556383507,
"over_mask": {
"encoding": "base64",
"format": "image/png",
"value": "iVui998...GdffrUI"
},
"l_hist": "KP/Hkn8rKC...4tHy8wKiYg",
"l_mean": 60.45518132141083,
"l_std": 85.83927935975983
},
"sharpness": {
"val": 500.15063266889683,
"sml": 43.20884422110553,
"val_norm": 0.5001506326688968,
"sml_norm": 0.28805896147403687
},
"noise": ""
},
"details": {
"name": "quality",
"score": 0,
"message": "",
"info": {
"description": ""
}
},
"version": "1.1.3.14"
}
curl -F 'image=@“/Users/Pictures/image.jpg”’ -X POST https://api.core.ltutech.com/v2/services/image/imageQuality -F 'bins=255' -F 'tolerence=0.1' --header "authorization: Bearer $TOKEN"
import requests
url = "https://api.core.ltutech.com/v2/services/image/imageQuality"
headers = {
'authorization': Bearer {token}
}
with open(path_img, 'rb') as media:
img = media.read()
files = {
'image': img,
}
data = {
'bins': 255,
'tolerence': 0.01
}
result = requests.post(url,headers=headers, files=files).json()
Call this API point to perform Optical Character Recognition which detects printed and handwritten text in an image.

Build a POST request of type multipart/form-data(binary or text) or application/x-www-form-urlencoded(only text) to send the image and its properties.
POST https://api.core.ltutech.com/v2/services/image/textDetection
The function textDetection takes as input:
A JSON object containing text detected and its position in the image.
{
"message": "ok",
"code": "0",
"content": {
"image": {
"areas": {
"7cc2b040/0": {
"type": "input",
"boundingBox": {
"x": 38,
"y": 21,
"width": 384,
"height": 481
},
"resultInfo": {
"textDetection": {
"type": "summary",
"language": "fr",
"text": "MADE IN ITALY\n92200 NEUILLY\nLE ROUGE CRAYON\nDE COULEUR MAT\nJUMBO L\u00c8VRES MAT\nLONGUE TENUE\n",
"subarea": [ "7cc2b040/1", "7cc2b040/2", "7cc2b040/3", ...],
"words": {
"MADE": ["7cc2b040/1"],
"IN" : ["7cc2b040/2"]
...
},
}
}
},
"7cc2b040/1": {
"type": "output",
"boundingBox": {
"x": 186,
"y": 23,
"width": 28,
"height": 9
},
"resultInfo": {
"textDetection": {
"type": "words",
"language": "en",
"text": "MADE"
}
}
},
...
}
"UUID": "7cc2b040",
"version": 0.1
},
"summary": {
"name": "textDetection",
"status": 0,
"message": "OK",
"resultInfos": {
"textDetection": {
"nbAreas": 25
}
}
},
"errors": []
}
}
curl -F 'image=@“/Users/Pictures/chanel-crayon.jpg”’ -X POST https://api.core.ltutech.com/v2/services/image/textDetection --header "authorization: Bearer $TOKEN"
import requests
url = "https://api.core.ltutech.com/v2/services/image/textDetection"
headers = {
'authorization': Bearer {token}
}
with open(path_img, 'rb') as media:
img = media.read()
files = {
'image': img,
}
result = requests.post(url,headers=headers, files=files).json()
Call this API point to perform label prediction of an image.
Build a POST request of type multipart/form-data(binary or text) or application/x-www-form-urlencoded(only text) to send the image and its properties.
POST https://api.core.ltutech.com/v2/services/image/classification
The function classification takes as input:
A JSON object containing labels list and a probability rates
{
"content": {
"labelAnnotations": [{
"score": 0.9805248379707336,
"topicality": 0.9805248379707336,
"mid": "/m/0215n",
"description": "Cartoon"
}, {
"score": 0.978813886642456,
"topicality": 0.978813886642456,
"mid": "/m/095bb",
"description": "Animated cartoon"
}, {
"score": 0.9443857669830322,
"topicality": 0.9443857669830322,
"mid": "/m/01k74n",
"description": "Facial expression"
}, {
"score": 0.7678998708724976,
"topicality": 0.7678998708724976,
"mid": "/m/0hcr",
"description": "Animation"
}, {
"score": 0.7291945219039917,
"topicality": 0.7291945219039917,
"mid": "/m/019nj4",
"description": "Smile"
}, {
"score": 0.7039424180984497,
"topicality": 0.7039424180984497,
"mid": "/m/0ds99lh",
"description": "Fun"
}, {
"score": 0.6912711262702942,
"topicality": 0.6912711262702942,
"mid": "/m/01kr8f",
"description": "Illustration"
}, {
"score": 0.6590808033943176,
"topicality": 0.6590808033943176,
"mid": "/m/02h7lkt",
"description": "Fictional character"
}, {
"score": 0.6522085666656494,
"topicality": 0.6522085666656494,
"mid": "/m/0jyfg",
"description": "Glasses"
}]
},
"message": "ok",
"code": "0"
}
curl -F 'image=@“/Users/Pictures/image.jpg”’ -X POST https://api.core.ltutech.com/v2/services/image/classification --header "authorization: Bearer $TOKEN"
import requests
url = "https://api.core.ltutech.com/v2/services/image/classification"
headers = {
'authorization': Bearer {token}
}
with open(path_img, 'rb') as media:
img = media.read()
files = {
'image': img,
}
result = requests.post(url, headers=headers, files=files).json()
The file and the headers objects are dictionaries that contains the expected name and the value of the parameters.
Call this API point to perform objects detection and localize them.

Build a POST request of type multipart/form-data(binary or text) or application/x-www-form-urlencoded(only text) to send the image and its properties.
POST https://api.core.ltutech.com/v2/services/image/objectDetection
The function objectDetection takes as input:
A JSON object containing a list of objects description, their probality rates and their position in the image
{
"content": {
"localizedObjectAnnotations": [{
"score": 0.6799721717834473,
"mid": "/m/01g317",
"boundingPoly": {
"normalizedVertices": [{
"y": 0.5424494743347168,
"x": 0.6926446557044983
}, {
"y": 0.5424494743347168,
"x": 0.8713106513023376
}, {
"y": 0.969238817691803,
"x": 0.8713106513023376
}, {
"y": 0.969238817691803,
"x": 0.6926446557044983
}]
},
"name": "Person"
}, {
"score": 0.6125506162643433,
"mid": "/m/0jbk",
"boundingPoly": {
"normalizedVertices": [{
"y": 0.7334161400794983,
"x": 0.8467774391174316
}, {
"y": 0.7334161400794983,
"x": 0.9417657256126404
}, {
"y": 0.9152880311012268,
"x": 0.9417657256126404
}, {
"y": 0.9152880311012268,
"x": 0.8467774391174316
}]
},
"name": "Animal"
}, "message": "ok",
"code": "0"
}
curl -F 'image=@“/Users/Pictures/image.jpg”’ -X POST https://api.core.ltutech.com/v2/services/image/objectDetection --header "authorization: Bearer $TOKEN"
import requests
url = "https://api.core.ltutech.com/v2/services/image/objectDetection"
headers = {
'authorization': Bearer {token}
}
with open(path_img, 'rb') as media:
img = media.read()
files = {
'image': img,
}
result = requests.post(url,headers=headers, files=files).json()
The files and the headers objects are dictionaries that contains the expected name and the value of the parameters.
LTU Core API could also be used to compare two images to
Call this API point to compute distance between two images for a matching signature:
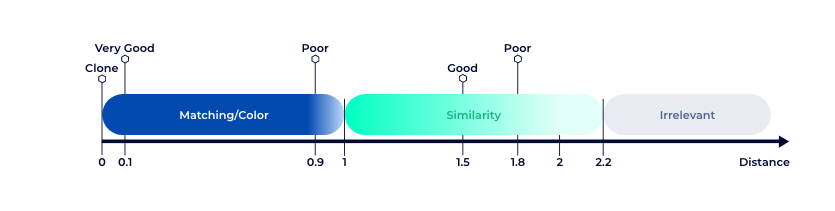
Build a POST request of type multipart/form-data(binary or text) or application/x-www-form-urlencoded(only text) to send the image and its properties.
POST https://api.core.ltutech.com/v2/services/image/distance
The function distance takes as input:
A Json result that contains the distance between the two images and for each image the coordinate of the most interesting points area. The info key contains the decition that indicates if images match or not.
{
{
"details": {
"name": "distance",
"score": 0,
"message": "Decision from distance calculation: Match",
"info": {
"distance": 0.8046875,
"decision": "Match"
}
},
"code": 0,
"errors": [],
"source": {},
"version": "0.1.0",
"result": {
"distance": 0.8046875,
"scores": {
"boxCoveredSurface": 0.3333333432674408,
"boxPointsRatio": 0.2678571343421936,
"boxPointsRatioHomography": 0.8571428656578064,
"matchStrength": 0.1953125,
"matchStrengthWithoutWeighting": 0.048828125
},
"query": {
"area": 0.12721012346446514,
"resizedDimensions": [512, 380],
"originalDimensions": [600, 550],
"matchingBox": [[0.11328125, 0.1315789520740509], [0.357421875, 0.1315789520740509],[0.357421875, 0.6526316404342651],[0.11328125, 0.6526316404342651]]
},
"reference": {
"area": 0.05167242884635925,
"resizedDimensions": [
512,
469
],
"originalDimensions": [
600,
550
],
"matchingBox": [[0.5078125, 0.336887001991272],[0.6796875, 0.336887001991272],[0.6796875, 0.6375266313552856],[0.5078125, 0.6375266313552856]]
}
}
}
}
curl -F 'image=@“/Users/Pictures/image1.jpg”’ -F 'image=@“/Users/Pictures/image2.jpg”’ -X POST https://api.core.ltutech.com/v2/services/image/distance --header "authorization: Bearer $TOKEN"
import requests
url = "https://api.core.ltutech.com/v2/services/image/distance"
headers = {
'authorization': Bearer {token}
}
with open(path_img1, 'rb') as media:
img1 = media.read()
with open(path_img2, 'rb') as media:
img2 = media.read()
files = {
'refImage': img1,
'queryImage': img2
}
result = requests.post(url, headers=headers, files=files).json()
The files and headers objects are dictionaries that contains the expected name and the value of the parameters.
Call this API point to compute fine images comparison between two images and get the differences.

Build a POST request of type multipart/form-data(binary or text) or application/x-www-form-urlencoded(only text) to send the image and its properties.
POST https://api.core.ltutech.com/v2/services/image/differences
The function differences returns many possible ressults, according of your needs. The complete setting gives you more details about the differences (area, coordonnates, matrices, binary mask...)
It takes as mandatory inputs:
A set of parameters to apply to calculate the differences, availale in two forms. As a predefined setting:
Or instead of sending a predefined setting, you can specify each parametters definded in a json format:
And as optional inputs:
Finaly, the detailled version can also return visual masks for each difference's area. That could be useful to quickly display the differences. Thus, you can specify:
A JSON object containing :
If transform=true:
The content of the fields diffOnImage1 and diffOnImage2 is different and will be detailed below.
Here is an example of the JSON where diffOnImage1 and diffOnImage2 fields are collapsed to simplify it:
{
result: {
diffOnImage1: [],
diffOnImage2: [],
}
details: {
name: "differences",
score: 1.712538719177246,
message: "",
info: {
count: 1
}
},
version: "0.1.0"
}
The image parts reveal details all the informations relative to the images differences. The structure of this part is common to all images. diffOnImage1 and diffOnImage2 are lists of differences detailled according what is specified in the request. The fields of an image difference are:
diffOnImage1: [
{
boundingBox: {
x: 241,
y: 140,
width: 21,
height: 22
},
enclosingCircle: {
radius: 14.354637145996094,
center: {
x: 252.26922607421875,
y: 150.5
}
},
relativeVertices: [
{
x: 8,
y: 0
},
...
],
"mask": {
value: "iVBORw0KGgoAA...ABJRU5ErkJggg==",
format: "image/png",
encoding: "base64"
}
]
For the binaryMask the fields provided are:
Could containt the binary mask or the differences contours.
"binaryMask": {
"encoding": "base64",
"format": "binary",
"value": "iVBORw0KGgoAAAANSUhEUgAAACQAAAAqCAYAAADbCvnoAAAByklEQVRYCc3BUW5iQRRDweOF+8sL90it0RUdXuBBIKFKnFYzFK7UDIUnidNqhsKhGhSoQeEJ4rSajcKhmqHwIHFKzUbhphoUniDuqtko3FWDwhPEXTVD4a6aobDUoHCCOKUGhdNqDincITY1KCw1KDytBoWlBgVqULhBjJpDCi9RMxS+IZYaFKhBYalB4aVqULhBUDMU/phYalD4AOLDiA8jPoz4MGKpWRTeqgaFGwQ1G4W3qBkK3xBLzUbhLWpQuEFsalA4VIPCoRoUDtWgcJIYNUNhUzMUNjVDYVMzFE4QmxoUDtUMhaVmKByqQeEkcVrNUBg1KLyIeEjNUHgD8bAaFEYNCi8iHlIzFKjZKPyQOK1mKIyajcJSg8KDxENqhsKo+ZbCA8SVGhQO1QyFKzUoLDUoUIPCUoPCDWJTMxQ2NUPhlJpDCt8Qm5qhcKUGhYfUoLDUoHCDWGoWBWpQeLsaFL4Q1GwU3q5mKFwQS82i8GtqUPhCUDMUfk0NCl8IahaFX1MzFC4IaobCr6lB4QtBzaLwNjUojBoUDogrNSi8TM1QoGYoUIPCf2JTMxR+rGYojJorCtTiSg0KL1ODwpUaFKi5IP5czYV/4XvIn8Nb0h8AAAAASUVORK5CYII="matrices,
}
curl -d 'image1=http://data.onprint.com/ltu-core-api/16-1.png' -d 'image2=http://data.onprint.com/ltu-core-api/16-2.png' -d 'preset=4' -X POST https://api.core.ltutech.com/v2/services/image/imagesDifferences --header "authorization: Bearer $TOKEN"
import requests
url = "https://api.core.ltutech.com/v2/services/image/aligmentMatrix"
headers = {
'authorization': Bearer {token}
}
with open(path_img1, 'rb') as media:
img = media.read()
with open(path_img2, 'rb') as media:
img = media.read()
files = {
'image1' : img1,
'image2' : img2
}
data = {
'output_format': 'json',
'version' : "Custom",
'mask_type': None,
'mask_thickness': 2,
'mask_color': "255,0,0,125",
'vertices': True,
'fic_settings' : '{
'resolution': 600,
'threshold': 1.4,
'smooth': 1.4,
'margin': 0
}'
}
result = requests.post(url, headers=headers, files=files, data=data).json()
The data, files and headers objects are dictionaries that contains the expected name and the value of the parameters.
Call this API point to get the matrices that allow to align two images with several common key points. This function could be useful to present results after a differences search processing or finding objects.

Build a POST request of type multipart/form-data(binary or text) or application/x-www-form-urlencoded(only text) to send the image and its properties.
POST https://api.core.ltutech.com/v2/services/image/alignmentMatrix
The function colorPalette takes as input:
A JSON object containing the transformation matrices of one image compared to a second and vice-versa.
{
"result": {
"matrix1": [
0.9577863670219944,
0.13542988533171293,
15.033106128257174,
-0.1172470682393062,
0.9729115471192803,
53.000515419363,
0.00012152501983124229,
0.0002784131036308724,
1
],
"matrix2": [
1.0278529957789055,
-0.1407913663551346,
-7.989808186372866,
0.1326851809104355,
1.0254972122818815,
-56.346551218333204,
-0.00016185114871873144,
-0.00026840218804783083,
1.016658579801889
]
},
"details": {
"name": "alignmentMatrix",
"score": 0,
"message": "Alignment Matrices properly calculated",
"info": {}
},
"version": "0.1.0"
}
curl -d 'image1=http://data.onprint.com/ltu-core-api/16-1.png' -d 'image2=http://data.onprint.com/ltu-core-api/16-2.png' -d 'resolution=512' -X POST https://api.core.ltutech.com/v2/services/image/alignmentMatrix --header "authorization: Bearer $TOKEN"
import requests
url = "https://api.core.ltutech.com/v2/services/image/alignmentMatrix"
headers = {
'authorization': Bearer {token}
}
with open(path_img1, 'rb') as media:
img1 = media.read()
with open(path_img2, 'rb') as media:
img2 = media.read()
files = {
'image1': img1,
'image2': img2
}
data = {
'resolution': 512
}
result = requests.post(url, headers=headers, files=files, data=data).json()
The data, files and headers objects are dictionaries that contains the expected name and the value of the parameters.
∴
That's it! You went through all our documentation. We hope you liked it. We would love to hear from your feedback, so for anything please contact us! You can now start ahead, and if you need more, don't forget the reference documentation.
We also have a Swagger page, useful to test a little. You can find it here: https://swagger.dev.ltutech.com/?urls.primaryName=Core

Thank you for your interest in the LTU API. Any question let us know.