Get Developer Support
Request Developer Access

A Document as we defined it at LTU, is one image or a set of images to which we associate actions (consult an url, send an email...) and that must be activated to be recognized and allows Users to access to these actions.
This API has been developed to allow you to be autonomous in adding documents, creating ans stylizing actions and/or developing your own search application. Here we will guide you from the authentication on the service until the click on an action.
We have also developed a simpler API that just allow to identify an image and get its potential metadata. To know more you can consult the documentation of the Picture API
Request AccessTo get access to our services, you will need an account.
To request an account to our development team, please fill in that request form.
Contact UsShould you have any feedback or question please feel free to contact us.
-> To go deeper, the full API reference documentation is available here.
-> JQuery code samples come from the Javascript SDK (GitHub)
To have access to our service you must be logged. It means you need an account. With your API Key - that you get on the platform in the admin tab - and with your login, you get an token. This token must be send with all the add/get requests and is valid for 15 days.
Build a POST request of type application/x-www-form-urlencoded.
POST https://api.onprint.com/token
ApiKey:[your Api Key]
data:
grant_type:
username : your login account
password : your password
The content is form-data, built like this:
grant_type=password&username=toto@ltu.com&password=test
A Json containing the account data and the access token
curl -X POST -H "contentType: application/x-www-form-urlencoded" "https://api.onprint.com/token" -d "grant_type=password&username=toto@ltu.com&password=test" -H "ApiKey:[your API key]"
function login(username, password, apikey, callback) {
if (username == '' || password == '') {
alert('missing username or password');
return;
}
var url = 'https://api.onprint.com/token';
var formData = 'grant_type=password&username=' + encodeURIComponent(username) + '&password=' + encodeURIComponent(password);
$.ajax({
url: url,
type: 'POST',
accept: 'application/json',
headers: {
'ApiKey': apikey
},
contentType: 'application/x-www-form-urlencoded',
data: formData,
success: function (data, status) {
$.ajaxSetup({ beforeSend: function (xhr) {
xhr.setRequestHeader('Authorization', 'bearer ' + data.access_token);
} });
callback(data, status);
},
error: function (xhr, status) {
callback(xhr, status);
}
});
}
The response contains the token in the field access_token. It has an expiration date. It also contains your userId as well as your organizationId
{"access_token":"AQAAANCMnd8BFdERjHoAwE_Cl-sBAAAAET6D6vU6i0Kl63(...)","token_type":"bearer","expires_in":1209599,"userName":"toto@toto.com","userId":"085201a8-98a2-0f5c-3311-aa415563ed05","organizationId":"1a855da8-4510-0f5c-3311-aa415563da95","organizationName":"totorg","roles":"System.Data.Entity.DynamicProxies.UserRole_CDCE067A6D23","apiversion":"2.0.6",".issued":"Thu, 09 Feb 2017 15:51:04 GMT",".expires":"Thu, 23 Feb 2017 15:51:04 GMT"}
Use the OAuth2 authentication for API calls that requires it. Set a header in your get/add requests like this:
Authorization: Bearer AQAAANCMnd8BFdERjHoAwE_Cl-sBAAAAET6D6vU6i0Kl63(...)
Enrich a document means uploading an image or a pdf, associating actions to it and activate it.
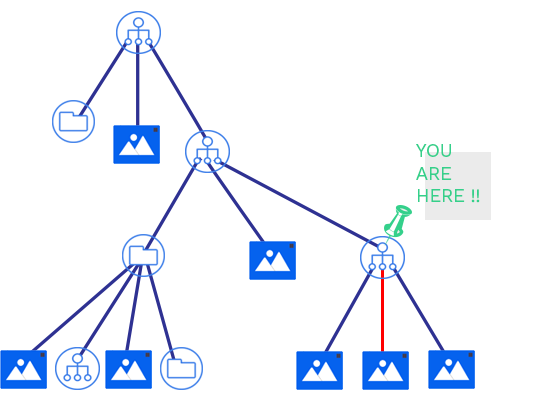
When you log in, you access to your parent organization (often it's your enterprise name) and all its children, which can be other organizations (your clients), folders or documents. These are called nodes. To navigate through the node arborescence, you can use the nodes endpoint.
As you may have noticed in part 1, when you log in, in return you get your own userId as well as your organizationId. If you want to see what nodes are children of your organization, try:
GET https://api.onprint.com/api/nodes/[your orgId]/nodes
And if you want to go deeper in the arborescence, use the same syntaxe using any other node Id.
GET https://api.onprint.com/api/nodes/[nodeId]/nodes
You have a possibility to only get the organizations, folders or documents of a node separately. This is the same idea but with other endpoints:
GET https://api.onprint.com/api/nodes/[nodeId]/documents
GET https://api.onprint.com/api/nodes/[nodeId]/folders
GET https://api.onprint.com/api/nodes/[nodeId]/organizations
"Authorization: bearer ${TOKEN}"
A JSON object with the nodes children's data.
curl -H "Authorization: bearer ${TOKEN}" https://api.onprint.com/api/nodes/[nodeId]/nodes
For typename in nodes, documents, folders, organizations, images, actions:
function getChildren(nodeId, typename, callback) {
$.ajax({
method: 'GET',
url: getUrl('/api/nodes/' + nodeId + '/' + typename),
success: function (data, status, xhr) {
callback(data, status, xhr);
},
error: function (xhr, status) {
callback(null, status, xhr);
}
});
}
When you want to create a new document, you can POST a multipart/form-data request. You have to specify the Id of the node (parent Id) where add the document. The node details are given as a JSON object in the body.
POST https://api.onprint.com/api/documents
The response is a JSON object representing the new document. HTTP status is 201 - Created.
curl -s -i -F 'document={"Name":"toto","ContentType":"image/jpeg","DefaultLanguage":"fr-FR","ParentId":"[Node ID]"};type=application/json' -F 'file=@/Users/image.jpeg;type=image/jpeg;filename=test.jpg' -X POST -H 'Content-type: multipart/form-data' -H 'Accept: application/json' -H "Authorization: bearer ${TOKEN}" 'https://api.onprint.com/api/documents?async=false'
For typename in nodes, folders, organizations, actions:
function postOne(object, typename, callback) {
$.ajax({
method: 'POST',
url: 'https://api.onprint.com/api/' + typename,
data: JSON.stringify(object),
contentType: 'application/json',
dataType: 'json',
success: function (data, status, xhr) {
callback(data, status, xhr);
},
error: function (xhr, status) {
callback(null, status, xhr);
}
});
}
Several properties are filled:
{
"Id": "31140da6-b422-44fd-82c1-847820f954e7",
"ParentId": "37e2cc76-8fcb-4864-9557-866d4bd47316",
"DefaultLanguage": "fr-FR",
"Name": "Cats in action",
"ContentType": "image/png",
"Pages": 1,
"AutoTrigger": false,
"ActionCount": 0,
"ErrorCount": 0,
"Status": "Inactive",
"Cover": "https://api.onprint.com/Files/Thumbs/1/6/0/31140da6-b422-44fd-82c1-847820f954e7/Cover.jpg",
"Conflict": -1,
"DateCreated": "2016-11-24T11:56:42Z",
"DateModified": "2016-11-25T12:51:15Z"
}
Here, we will focus on the document creation because it's the container of enriched images. But you can create Organisation and Folder to organize your documents. All the information on how to create any other node will be found in the API reference.
POST https://api.onprint.com/api/[organizations, folders or documents]
The request body content type must be Multipart (multipart/form-data). The content is made of a File data (named file) and a Form data (named document). If you don't know how to make a Multipart request, see the RFC 1341 part 7.2, or Java, NodeJS, .NET tools.
The document itself. It can be a JPEG, PNG, GIF image, or a PDF document. The MIME type has to be given in the file content type. There is no special requirement regarding file size or quality. However, you must keep in mind that to be recognized, the image must contain enough details or points. And if you send us a 3 Gigabytes PDF containing very high quality images, it will be slow and won't be particularly helpful because the platform resizes the images for recognition.
Contains a JSON object named document. The mandatory fields are:
{
"ParentId": "5215adae-e451-44c8-a930-9e4afe88bba9",
"DefaultLanguage": "fr-FR",
"Name": "Mathilde"
}
file parameter of function postDocument must be a binary file.
function getBoundary() {
return 'XXX' + (new Date).getTime() + 'XXX';
}
function createFileContent(filename, attachmentname, filetype, boundary) {
var contentFile = '--' + boundary + '\r\n';
contentFile += 'Content-Disposition: attachment; name=' + attachmentname + '; filename="' + filename + '"\r\n';
contentFile += 'Content-Type: ' + filetype + '\r\n';
contentFile += '\r\n';
return contentFile;
}
function createFormContent(object, objectname, boundary) {
var contentForm = '--' + boundary + '\r\n';
contentForm += 'Content-Type: application/json; charset=utf-8\r\n';
contentForm += 'Content-Disposition: form-data; name=' + objectname + '\r\n';
contentForm += '\r\n';
contentForm += JSON.stringify(object) + '\r\n';
return contentForm;
}
function postDocument(file, document, async, callback) {
var boundary = getBoundary();
var contentForm = createFormContent(document, 'document', boundary);
var contentFile = createFileContent(file.name, 'file', file.type, boundary);
var blob = new Blob([contentForm, contentFile, file, createEndContent(boundary)]);
$.ajax({
method: 'POST',
url: 'https://api.onprint.com/api/documents?async=' + async),
data: blob,
contentType: 'multipart/form-data; boundary="' + boundary + '"',
dataType: 'json',
processData: false,
success: function (data, status, xhr) {
callback(data, status, xhr)
},
error: function (xhr, status) {
callback(null, status, xhr)
}
});
}
In the URL, a parameter named async can be set like this:
POST /api/Documents?async=true
Defaults to true if not set. When this parameter is true, the image creation is made asynchronously and the method returns directly. When it is false, the method waits for the image creation before returning. The difference between both methods is important in the case of a PDF file.
If you could get a 201 status and a Document Id in the response, congratulations! You've done the most complicated part. The document has been created. If it was a single image, it will contain one image. If the input was a PDF, a process created one image per PDF page. LTU definition of an image is also a node, which can only be the direct child of a document.
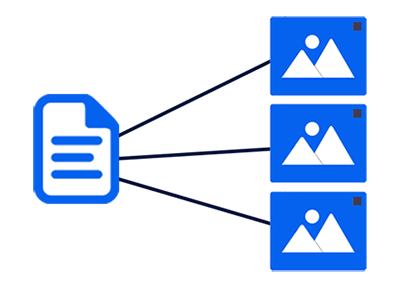
When you enrich an image, you add actions to an image (and not to a document). Before adding any action, get the images like this:
GET https://api.onprint.com/api/documents/[Document Id]/images
The response is a JSON object with a list of images's details.
curl -H "Authorization: bearer ${TOKEN}" 'https://api.onprint.com/api/documents/[Document Id]/images'
function getImages(docid, callback) {
$.ajax({
method: 'GET',
url: getUrl('/api/documents/' + docid + '/images'),
success: function (data, status, xhr) {
callback(data, status, xhr);
},
error: function (xhr, status) {
callback(null, status, xhr);
}
});
}
The response will look like (for a 2 page PDF):
[
{
"Id": "0590a3a5-c72e-4fec-8276-47023d085d7b",
"DocumentId": "9400c23a-78b0-48c5-8174-412349f6f702",
"Status": "Inactive",
"Name": "Page 1",
"Quality": -1,
"ActionCount": 0,
"ZoneCount": 0,
"Order": 1,
"AutoTrigger": true,
"Height": 1754,
"Width": 1240,
"Conflict": -1,
"SmallThumbnail": "https://api.onprint.com/Files/Thumbs/9/4/0/9400c23a-78b0-48c5-8174-412349f6f702/0590a3a5-c72e-4fec-8276-47023d085d7b/100.jpg",
"BigThumbnail": "https://api.onprint.com/Files/Thumbs/9/4/0/9400c23a-78b0-48c5-8174-412349f6f702/0590a3a5-c72e-4fec-8276-47023d085d7b/700.jpg",
"DateCreated": "2016-06-09T09:53:15Z",
"DateModified": "2016-07-15T09:42:11Z"
},
{
"Id": "0f743211-3864-4605-99b7-b2c75bf7b9f2",
"DocumentId": "9400c23a-78b0-48c5-8174-412349f6f702",
"Status": "Inactive",
"Name": "Page 3",
"Quality": -1,
"ActionCount": 0,
"ZoneCount": 0,
"Order": 3,
"AutoTrigger": false,
"Height": 1754,
"Width": 1240,
"Conflict": -1,
"SmallThumbnail": "https://api.onprint.com/Files/Thumbs/9/4/0/9400c23a-78b0-48c5-8174-412349f6f702/0f743211-3864-4605-99b7-b2c75bf7b9f2/100.jpg",
"BigThumbnail": "https://api.onprint.com/Files/Thumbs/9/4/0/9400c23a-78b0-48c5-8174-412349f6f702/0f743211-3864-4605-99b7-b2c75bf7b9f2/700.jpg",
"DateCreated": "2016-06-09T09:53:15Z",
"DateModified": "2016-06-09T09:53:15Z"
}
]
We will not get into all the parameters in detail, but we will remark several things here:
If you have uploaded a single image and not a PDF, the result would be the same with only one image, order 1. Note that the result is always an array.
[
{
"Id": "5ab18764-3ba5-476f-90ec-037299fa9d84",
"DocumentId": "1cdf40b8-4490-4527-a1c3-28e323ffa698",
"Status": "Active",
"Name": "Page 1",
"Quality": -1,
"ActionCount": 0,
"ZoneCount": 0,
"Order": 1,
"AutoTrigger": false,
"Height": 796,
"Width": 710,
"Conflict": -1,
"SmallThumbnail": "https://api.onprint.com/Files/Thumbs/1/c/d/1cdf40b8-4490-4527-a1c3-28e323ffa698/5ab18764-3ba5-476f-90ec-037299fa9d84/100.jpg",
"BigThumbnail": "https://api.onprint.com/Files/Thumbs/1/c/d/1cdf40b8-4490-4527-a1c3-28e323ffa698/5ab18764-3ba5-476f-90ec-037299fa9d84/700.jpg",
"DateCreated": "2017-02-01T11:44:04Z",
"DateModified": "2017-02-01T11:44:04Z"
}
]
Once you have the images, you will be able to add actions to them. This is where the enrichment begins. Note that you can also add global actions to the whole document, or even to any parent node. They will be set in every images. It is also possible to define zones in every image and then attach actions to zones (and not the full page). But for now, we'll focus on the most simple actions.
You may get used to the resource access; you'll easily guess the url to create a new action:
POST https://api.onprint.com/api/actions
{
"NodeId": "a46f43de-16df-4368-aa8b-81e1968e32a8",
"LanguageCode": "fr-FR",
"Name": "Visit our website",
"Type": "URL",
"Content": "{\"Url\": "http://www.monsuperwebsite.com\", \"ContentType\":\"text/html\"}"
}
As you can see, the special thing about the action is that the content is a serialized JSON object. This is necessary for the common action types, so that they can be validated, and understood when being scanned. You can see all the action types and content specificities in the reference documentation.
If you don't want the server to interpret the content and use it in your own mobile application, you can create an action of type "DATA", with the content you want. It will be stored "as is" and returned when you scan the image.
A JSON objects with a list of actions detail.
curl -X POST -H 'Content-type: application/json' -H 'Accept: application/json' -d "{'NodeId': '[Node Id]','LanguageCode': 'fr-FR','Name': 'Visit our website','Type': 'URL','Content': '{\"Url\": \"http://www.monsuperwebsite.com\", \"ContentType\":\"text/html\"}'}" -H "Authorization: bearer ${TOKEN}" 'https://api.onprint.com/api/actions'
function postOne(object, typename, callback) {
$.ajax({
method: 'POST',
url: 'https://api.onprint.com/api/' + typename,
data: JSON.stringify(object),
contentType: 'application/json',
dataType: 'json',
success: function (data, status, xhr) {
callback(data, status, xhr);
},
error: function (xhr, status) {
callback(null, status, xhr);
}
});
}
Here is the JSON response of our POST:
{
"Id": "31ee17d9-6cd5-4fc0-9d96-1dc0e19bc67a",
"NodeId": "a46f43de-16df-4368-aa8b-81e1968e32a8",
"IsValid": true,
"LanguageCode": "fr-FR",
"Distance": 0,
"Priority": 0,
"Order": 0,
"Name": "Visit our website",
"Type": "URL",
"Content": "{\"Url\":\"http://www.monsuperwebsite.com\",\"IsEmbeddedWebView\":false,\"IsAnonymousURL\":false,\"ContentType\":\"text/html\"}",
"DateCreated": "2017-02-15T13:42:25Z",
"DateModified": "2017-02-15T13:42:25Z"
}
For a DATA action with any random content, the action created looks like:
{
"Id": "9766ce45-42cc-4dce-8299-90d9f9138589",
"NodeId": "a46f43de-16df-4368-aa8b-81e1968e32a8",
"IsValid": true,
"LanguageCode": "fr-FR",
"Distance": 0,
"Priority": 0,
"Order": 0,
"Name": "Some data",
"Type": "DATA",
"Content": "Hello ca va, type 0=value1 string to parse..444de5fg1",
"DateCreated": "2017-02-15T14:00:15Z",
"DateModified": "2017-02-15T14:00:15Z"
}
When you get the list of actions
GET api.onprint.com/api/nodes/[nodeId]/actions
same as getting the images or any list, they are not ordered. You have 2 fields for that, Priority and Order. Actions will be ordered on our smartphone app by priority and then by order, but if you write yours, you can use it as you wish.
The Distance concerns the position of the action in the node tree.
You can also set a Style for the action (colors, text...). Syntax for our platform is detailed in the reference documentation; but you can create your own visual model and put anything you want in this field.
It's now time to activate the document, so that its images can be recognized and associated to the actions. In fact, you can do this step at any time, but nothing will be visible if there is no action attached to any image of the document.
To do it, it's only a little PATCH on the whole document:
PATCH api.onprint.com/api/documents?id=[documentId]
with the new Status in the body:
{
"Status": "Active"
}
Normal response is 204 - No Content.
curl PATCH -H 'Content-type: application/json' -H "Authorization: bearer ${TOKEN}" -d "{'Status': 'active'}" 'https://api.onprint.com/api/documents?id=[Document Id]'
function activateDocument(docid, callback) {
var doc = {
Status : 'Active'
};
$.ajax({
method: 'PATCH',
url: 'https://api.onprint.com/api/documents?id=' + docid,
data: JSON.stringify(doc),
contentType: 'application/json',
dataType: 'json',
success: function (data, status, xhr) {
callback(data, status, xhr);
},
error: function (xhr, status) {
callback(null, status, xhr);
}
});
}
Of course, once the document is active you can add, remove, edit actions of the document without having to deactivate / reactivate. All the modifications are taken into account.
In the URL, a parameter named async can be set like this:
PATCH /api/Documents?id=[documentId]&async=true
Defaults to true if not set. When this parameter is true, the activation is made asynchronously and the method returns directly. When it is false, the method waits for the image activation before returning. The difference between both methods can have an importance in the case of a PDF file.

For this part, we'll consider that we have enriched a picture on the LTU platform. For test purposes we have enriched this one already:

You can try and flash it with our Webapp ltutech.app. You'll see a list of actions of several types, with different styles.
Now we'll flash it programmatically, using the API. There are two entry points for it, search by Image or search by Id. This last one can be useful if you want to cache searches for example.
In both cases, these calls happen on the application side.
For an image search, it will be a multipart (multipart/formdata) POST:
POST https://api.onprint.com/api/EnrichedImages
LTU will require some information from the device to store useful clickstream information and to authenticate, using the API key. These calls do not need a oAuth authentication. This is why you will have to set several headers to the call. Below is the full list. You can also find it in the reference documentation.
| Header | Type | Example | Mandatory? |
|---|---|---|---|
| SessionId | Unique Identifier | 2252dda8-ce26-49d8-98e0-3fbe76181435 | |
| ApplicationInstanceId | Unique Identifier | CCE20149-0F83-43FE-A167-C4E1A3335FC9 | |
| ApplicationName | String | My Super App | * |
| ApplicationVersion | String | 1.7.4.121 | * |
| ApiKey | Unique Identifier | 3ad17b48a8a4f08f8949a | * |
| DeviceName | String | iPhone de Thomas | * |
| DeviceSystemVersion | String | 10.2.1 | * |
| DeviceSystemVersionName | String | iPhone OS | |
| SdkName | String | My Super App SDK | |
| SdkVersion | String | 1.7.4 | * |
| DeviceConnectivity | String | WiFi | |
| DeviceScreenDiagonal | String | 0 | |
| DeviceScreenHeight | String | 568 | |
| DeviceScreenWidth | String | 320 | |
| Longitude | Floating point | 44.946709 | |
| Latitude | Floating point | -93.175379 |
The mandatory headers are Application Name and version, Sdk version (if you are developing a single application, Sdk version = Application version), Device name and system version, and APIkey.
Once you are able to get all this information from the device, you are ready to do the request.
curl -s -i -F 'query={"Language":"fr-FR"};type=application/json' -F 'file=@/Users/onprint/veggies.jpeg;type=image/jpeg;filename=test.jpg' -X POST -H 'Content-type: multipart/form-data' -H 'Accept: application/json' -H 'ApiKey: [API key]' -H 'ApplicationInstanceId: ApiTester' -H 'ApplicationName: ApiTester' -H 'ApplicationVersion: 0.0' -H ‘DeviceName: Po -H 'DeviceSystemVersion: 0.0' -H 'DeviceSystemVersionName: Script' -H 'SdkName: Script' -H 'SdkVersion: 1.0' 'https://api.onprint.com/api/EnrichedImages'
function getBoundary() {
return 'XXX' + (new Date).getTime() + 'XXX';
}
function createFileContent(filename, attachmentname, filetype, boundary) {
var contentFile = '--' + boundary + '\r\n';
contentFile += 'Content-Disposition: attachment; name=' + attachmentname + '; filename="' + filename + '"\r\n';
contentFile += 'Content-Type: ' + filetype + '\r\n';
contentFile += '\r\n';
return contentFile;
}
function createFormContent(object, objectname, boundary) {
var contentForm = '--' + boundary + '\r\n';
contentForm += 'Content-Type: application/json; charset=utf-8\r\n';
contentForm += 'Content-Disposition: form-data; name=' + objectname + '\r\n';
contentForm += '\r\n';
contentForm += JSON.stringify(object) + '\r\n';
return contentForm;
}
function searchImage(file, searchQuery, callback) {
var query = {
Language : searchQuery.Language
};
var boundary = getBoundary();
var contentForm = createFormContent(query, "query", boundary);
var contentFile = createFileContent(file.name, "file", file.type, boundary);
var blob = new Blob([contentForm, contentFile, file, createEndContent(boundary)]);
$.ajax({
method: 'POST',
url: 'http://api.onprint.com/api/EnrichedImages',
data: blob,
contentType: 'multipart/form-data; boundary="' + boundary + '"',
dataType: 'json',
processData: false,
headers: {
'ApplicationInstanceId': searchQuery.ApplicationInstanceId,
'ApplicationName': searchQuery.ApplicationName,
'ApplicationVersion': searchQuery.ApplicationVersion,
'ApiKey': searchQuery.ApiKey,
'DeviceName': searchQuery.DeviceName,
'DeviceSystemVersion': searchQuery.DeviceSystemVersion,
'DeviceSystemVersionName': searchQuery.DeviceSystemVersionName,
'SdkName': searchQuery.SdkName,
'SdkVersion': searchQuery.SdkVersion,
'Latitude': searchQuery.Latitude,
'Longitude': searchQuery.Longitude
},
success: function (data, status, xhr) {
if (xhr.status == 200) {
}
if (xhr.status == 204) {
}
callback(data, status, xhr);
},
error: function (xhr, status) {
callback(null, status, xhr);
}
});
}
Example of response:
Here is an example of what you should get for the Vegetables image, with FormData query asking for French language:
{
"Id":"dfa031b2-2f50-4216-a78e-349b755f55fa",
"BigThumbnailUrl":"https://api.onprint.com/Files/Thumbs/d/0/4/d04bb5e5-1cfc-423a-8c29-eaccb0c43bc7/dfa031b2-2f50-4216-a78e-349b755f55fa/700.jpg",
"LanguageCode":"fr-fr",
"Title":"Les légumes c'est bon !",
"DocumentId":"d04bb5e5-1cfc-423a-8c29-eaccb0c43bc7",
"SessionId":"6cfa5f22-41ef-4a0b-a26b-deb48f2ca306",
"Order":0,
"AutoTrigger":false,
"TitleStyle":"",
"Data": "", //This field will always be empty, except when you scan a Picture, therefore you will have no Title, no Actions, no LanguageCode, no Styles, but one Data item.
"Actions":[
{
"Id":"6a36e317-ee23-4156-98cc-630e032ad354",
"Icon":"https://api.onprint.com/Icons/a/a2a3c5df-d5e3-490a-bca0-3c896c3539f8.png",
"Priority":-1,
"Order":2,
"Name":"En parler aux devs",
"Style":"{\"model\":\"ONPrint-V2.0\",\"button\":{\"background-color\":\"#0099ad\",\"opacity\":0.6},\"text\":{\"color\":\"#FFFFFF\",\"font-weight\":\"normal\",\"font-style\":\"normal\",\"opacity\":1}}",
"Type":"SMS",
"Content":"{\"Number\":\"+33761807984\",\"Content\":\"En fait j'adore les légumes !\"}"
},
{
"Id":"9fb0840d-8142-4511-b179-e846a5d67952",
"Icon":"https://api.onprint.com/Icons/a/a362bf3c-47d7-4ee2-9f48-cfe0400b38a8.png",
"Priority":-1,
"Order":1,
"Name":"Recette de poivrons",
"Style":"",
"Type":"URL",
"Content":"\"Url\":\"http://www.receptescartesianes.cat/recipes/76\",\"IsEmbeddedWebView\":true,\"IsAnonymousURL\":false,\"ContentType\":\"text/html\"}"
},
{
"Id":"af84c349-16ef-498d-a832-0cd880eb8710",
"Icon":"https://api.onprint.com/Icons/d/d0410ba6-0b37-47be-9486-8ef4d420d4c0.png",
"Priority":-1,
"Order":3,
"Name":"Se rendre au pays des courgettes",
"Style":"{\"model\":\"ONPrint-V2.0\",\"button\":{\"background-color\":\"#148c00\",\"opacity\":0.6},\"text\":{\"color\":\"#FFFFFF\",\"font-weight\":\"normal\",\"font-style\":\"normal\",\"opacity\":1}}",
"Type":"MAP",
"Content":"{\"Latitude\":null,\"Longitude\":null,\"SearchAddress\":\"2360 La Dorgale, 13360 ROQUEVAIRE\"}"
}
]
}
The query image itself. No need to make it big: our recommandation is to pre-treat it before sending to the server:
The MIME type will be image/jpeg.
Contains the Json query object that goes with the content. The parameter only contains one property: Language (string) containing a language code. The form data name is "query".
Example:
{
"Language":"fr-FR"
}
The en-US language will give you other results.
Once you have done this, you can try with any of your images and enjoy! Then it will be up to you to present them on your screen, the way you want, and trigger the actions when a user clicks on it.
To get the same result by providing the image Id only (no image search), you can call a GET:
GET https://api.onprint.com/api/EnrichedImages/[imageId]?languagecode="[query language code]"
The LTU platform stores every flash, so that you can get clickstream information. But to make this information coherent in complete, you will have to log the action clicks.

You may have noticed that when you searched for the image, you didn't give a SessionId in the header, but the server generated you one and gave it in the response (see previous example).
The SessionId is renewed at every flash, and corresponds to a "flash session" for a user, the typical scenario:
It will be useful to follow a user from the flash to the click on one or more actions. This session can also be followed by:
To track this kind of use cases, the SessionId generated by the server at the flash, and returned, has to be given back to the server when the user clicks on an action. So first thing to keep in mind is to store the SessionId in the EnrichedImages search response. Let's take the one of our previous example, it was
6cfa5f22-41ef-4a0b-a26b-deb48f2ca306
Everytime a user clicks on an action, you will create a new click:
PUT https://api.onprint.com/api/Clicks?actionId=[actionId]
With the same headers as for EnrichedImages, and SessionId made mandatory.
OK response will be 204 - NoContent.
curl -X PUT -H "Content-Length: 0" -H 'Accept: application/json' -H 'ApiKey: [API Key]' -H 'ApplicationInstanceId: ApiTester' -H 'ApplicationName: ApiTester' -H 'ApplicationVersion: 0.0' -H 'DeviceName: Me' -H 'DeviceSystemVersion: 0.0' -H 'DeviceSystemVersionName: Script' -H 'SdkName: Script' -H 'SdkVersion: 1.0' -H 'SessionId: [Session Id]' 'https://api.onprint.com/api/Clicks?actionId=[Action Id]'
function clickAction(actionId, headers, callback) {
$.ajax({
method: 'PUT',
headers: {
'ApplicationInstanceId': headers.ApplicationInstanceId,
'ApplicationName': headers.ApplicationName,
'ApplicationVersion': headers.ApplicationVersion,
'ApiKey': headers.ApiKey,
'DeviceName': headers.DeviceName,
'DeviceSystemVersion': headers.DeviceSystemVersion,
'DeviceSystemVersionName': headers.DeviceSystemVersionName,
'SdkName': headers.SdkName,
'SdkVersion': headers.SdkVersion,
'SessionId': headers.SessionId
},
url: 'http://api.onprint.com/api/Clicks?actionId=' + actionId,
success: function (data, status, xhr) {
callback(data, status, xhr);
},
error: function (xhr, status) {
callback(null, status, xhr);
}
});
}

This function is quite limited for the moment. It will give you the Matches on a given document (coming soon: the clicks too, and more query possibilities (image, node...)). For more complete statistics you can contact us and get a Reports application access. But it can help:
GET https://api.onprint.com/api/Matches?documentId=[documentId]
The response body will look like:
[
{
"SessionId": "ddf2b16f-83b8-42cf-8f24-d0f7bb26b32f",
"RequestTime": "2017-02-15T17:12:42",
"DeviceSystemVersion": "25",
"Language": "fr-FR",
"OperatingSystem": "Android",
"ImageOrder": 1,
"DocumentName": "Veggies",
"Host": "89.159.154.165"
},
{
"SessionId": "95dffb53-9d79-499b-926c-f1b8e0b3ab50",
"RequestTime": "2017-02-15T17:21:03",
"DeviceSystemVersion": "25",
"Language": "fr-FR",
"OperatingSystem": "Android",
"ImageOrder": 1,
"DocumentName": "Veggies",
"Host": "89.159.154.165"
},
{
"SessionId": "9026b2f0-4794-4f59-be68-fea61f98bb28",
"RequestTime": "2017-02-15T17:41:34",
"DeviceSystemVersion": "5.6.7",
"Language": "fr-FR",
"OperatingSystem": "Android",
"ImageOrder": 1,
"DocumentName": "Veggies",
"Host": "89.159.154.165"
}
]
There is also a compatibility between EnrichedImages and Pictures. You can use the EnrichedImages API to scan a Picture (the opposite is not true). The result will be a single (best recognition score) Enriched Image, with no language, no styles, only a "Data" field containing the picture data.
To get the same result by providing the image Id only (no image search), you can call a GET:
GET https://api.onprint.com/api/Pictures/[Id]"
The only difference is that the RecognitionScore will be null or 0.
The LTU platform stores every flash, so that you can get clickstream information.
∴
That's it! You went through all our QuickStart. We hope you liked it. We would love to hear from your feedback, so for anything please contact us! You can now start ahead, and if you need more, don't forget the reference documentation.
We also have a Swagger page, useful to test a little but not fully configured (missing headers for EnrichedImages and Clicks, so it won't work, multipart stuff a little handmade...). You can find it here: https://api.onprint.com/Swagger

Thank you for your interest in the LTU API. Any question let us know.